前言
本文是Stable Diffusion WebUI教程系列的第一篇,主要用于记录我个人折腾Stable Diffusion的经历,也希望能够给予看到本系列文章的每位伙伴,让我们一起拥抱属于AI的新时代。 本文的全部教程基于Automatic1111的Stable Diffusion WebUI项目,这也是目前最为主流的一个项目。该项目需要一定的命令行操作基础,建议学习基本的conda和git相关命令后再进行学习,当然如果没有学习过相关内容也可以直接复制本文的命令一步一步完成部署。其他形式的Stable Diffusion项目相关教程,可能会后面陆续推出。 本文的所有操作均基于windows10系统,其他系统类型可以参考,但未必全部适用。 GitHub项目地址:
相关阅读:AutoGPT部署指引 - 同样使用git和miniconda作为基本工具
部署教程
0. 硬件要求
需要你的电脑有Nvidia独立显卡(也就是俗称的N卡),主要对显存有要求,目前测试来看6G以上显存都可以基本运行。 内存:16G或以上 显卡显存:6G或以上 显卡型号:N卡,没有具体型号推荐,显存达标的前提下越新的型号运行会越快,目前我的硬件为3060 6G笔记本 硬盘:至少需要100G的空余空间,随着新的基础模型和Lora等的安装,所需空间还会越来越大,因此不建议安装在C盘
1. 工具准备
本文与之前的AutoGPT部署教程一样,会使用git和miniconda作为基本工具,用于拉取GitHub项目代码以及创建虚拟环境。如果不知道这两个工具如何下载,可以参考AutoGPT教程的第一部分:
相关阅读:AutoGPT部署指引
2. 环境及依赖准备
拉取项目
首先我们需要拉取项目的全部代码到本地,需要使用git工具。进入你希望部署项目的文件夹地址,我们这里依旧使用D:/playground作为所有AI项目的地址。 进入文件夹后,呼出右键菜单,点击”git bash here”,将会启动git的命令行页面。在命令行中输入如下命令并按下回车,将会创建一个名为”stable-diffusion-webui”的文件夹,并将项目的全部代码下载到该文件夹中
1 | |
运行完成后,全部内容都会被安装到D:/playground/stable-diffusion-webui中。 如果运行以上命令时发现运行速度很慢,也可以选择访问项目地址,选择右上角Code-Download ZIP,将下载到本地的压缩包解压到指定位置,可以达成一样的效果。(如果下载速度也比较慢,可以尝试使用迅雷下载,有奇效)
创建环境
该项目的环境依赖已经被编制为一个文件,存储在stable-diffusion-webui/environment-wsl2.yaml中。因此只需要引用该文件进行创建即可。 首先启动你的Anaconda Prompt(miniconda),conda将会默认运行在C盘目录下,需要切换目录到我们刚刚拉取项目的目录下。
1 | |
目录切换完成后,运行以下命令,将会在stable-diffusion-webui文件夹中创建automatic文件夹,并把虚拟环境安装在这个文件夹中。
1 | |
如果运行以上命令失败并报错”ResolvePackageNotFound: - cudatoolkit=11.8”,说明目前给出的conda源中无法获取到cudatoolkit,这是webui 1.1.0版本引入的一个新的问题,可以通过添加源来解决。具体步骤如下:
- 找到environment-ws12.yaml文件,用记事本打开
- 在channels中增加一个来源”conda-forge”,语法如图所示

- 保存文件,并重新在conda中运行前面的命令
注意yaml的语法,添加的源前面需要有两个空格并且加上-,否则是无效的。
安装依赖
除了运行环境之外,该项目运行还需要很多依赖包,所需的全部依赖已经全部写入文件requirements.txt中 首先需要激活之前创建好的环境:
1 | |
环境激活后,可以看到命令行中最前面的(base)改为(D:\playground\stable-diffusion-webui\automatic)这说明后面的命令已经在虚拟环境内运行。 下面运行以下命令:
1 | |
依赖比较多需要一段时间进行安装,如果中途发生失败,可以重新运行。根据不同的网络环境,可能会需要三四次安装过程才能完全成功。 请注意,必须要完全安装全部依赖后才能够进行后面的步骤。最后一步需要运行项目的执行文件,这将会安装最后的一部分依赖:
1 | |
3. 基础模型准备
要使用Stable Diffusion WebUI必须加载基础模型,基础模型一般是基于Stable Diffusion项目进行训练或微调出来的,将会决定你作图的基本画风(比如一个写实的模型很难画出漫画风格的内容)。 该项目中默认已经安装了stable diffusion 1.5版本的模型,在首次运行webui-user.bat后就会自动下载。但一般我们肯定不会满足于只有普通的1.5模型,因此需要去自行下载所需的其他基础模型。 这些基础模型可以在HuggingFace或者Civitai中找到,可以访问以下两个地址查找,访问C站可能需要一些魔法。
相关链接:HuggingFace | Civitai
本文以Stable Diffusion官方的2.1模型为例,在HuggingFace中搜索”stable-diffusion-2-1”,或者访问以下地址:https://huggingface.co/stabilityai/stable-diffusion-2-1/tree/main 其中会有多个版本的模型可以下载,但是对于初学者来说,用哪个版本区别并不大。我们这里选择”Files and versions”中”v2-1_768-ema-pruned.safetensors”文件进行下载,将下载好的模型放在D:\playground\stable-diffusion-webui\models\Stable-diffusion 文件夹中,这样该基础模型就可以被选择加载到你的webui里面了。 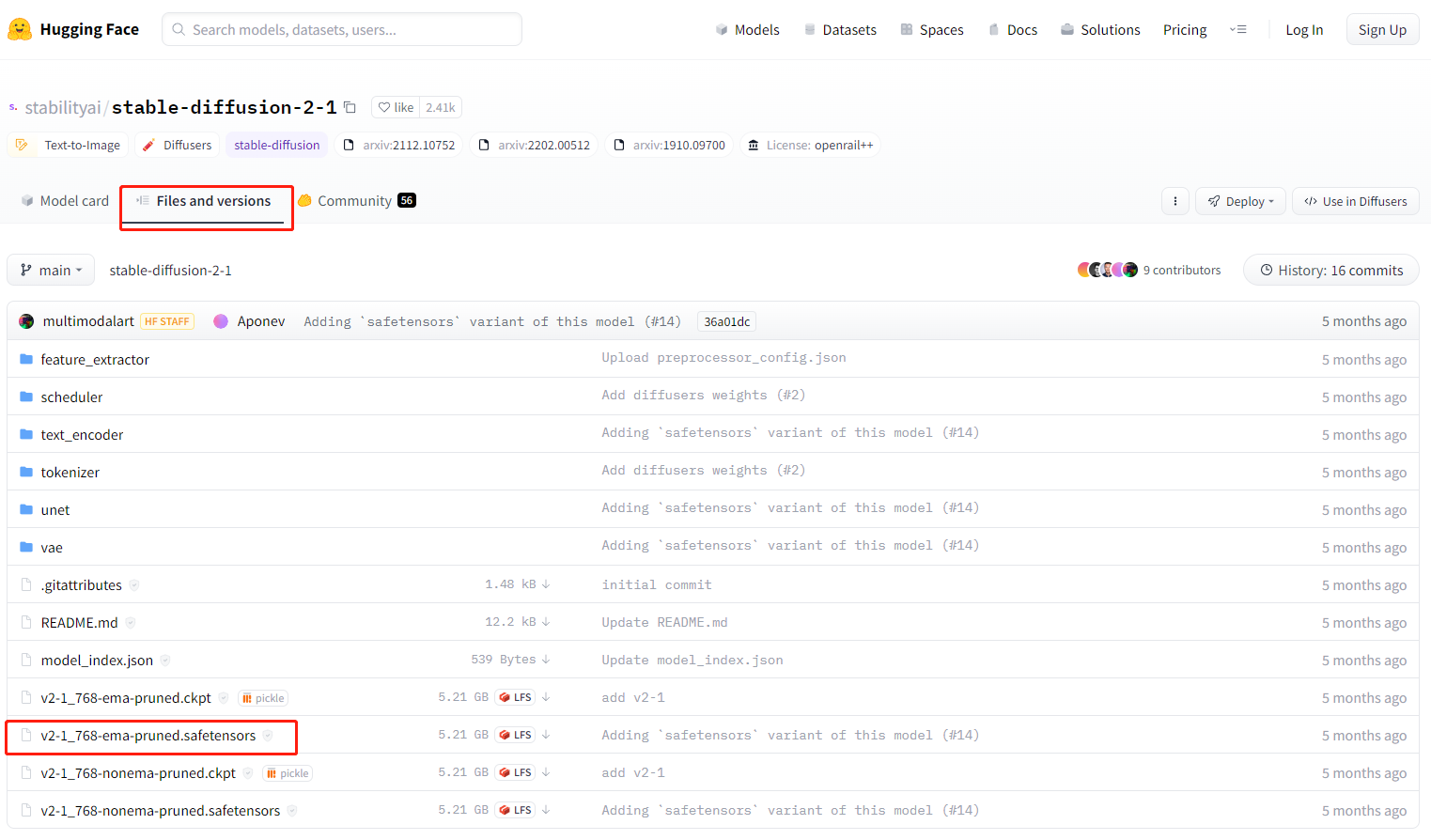 如果发现浏览器下载速度过慢,也可以选择用迅雷下载。
如果发现浏览器下载速度过慢,也可以选择用迅雷下载。
基础模型推荐
chilloutmix——一个专用于画美女的模型,写实画风,面部偏向于亚洲女性,比较容易少儿不宜。下载地址:https://civitai.com/models/6424/chilloutmix
Realistic Vision——一个超写实画风的模型,可以画出非常真实并且有丰富细节的画像,任务偏向于欧美。下载地址:https://civitai.com/models/4201/realistic-vision-v20
BRA(Beautiful Realistic Asians)——一个专门为亚洲面孔优化的模型,非常适用于绘画中日韩美女/帅哥。下载地址:https://civitai.com/models/25494/brabeautiful-realistic-asians-v5
4. 运行项目和基本使用
每次启动项目,需要启动Anaconda Prompt,先切换至项目所在目录,激活虚拟环境,运行”webui-user.bat”
1 | |
项目启动完成后,将会输出以下内容,其中172.0.0.1:7860(一般默认为该端口,如果遇到冲突也可能会自动生成其他端口),就是webui的访问地址。进入浏览器,输入以上地址即可进入webui页面。 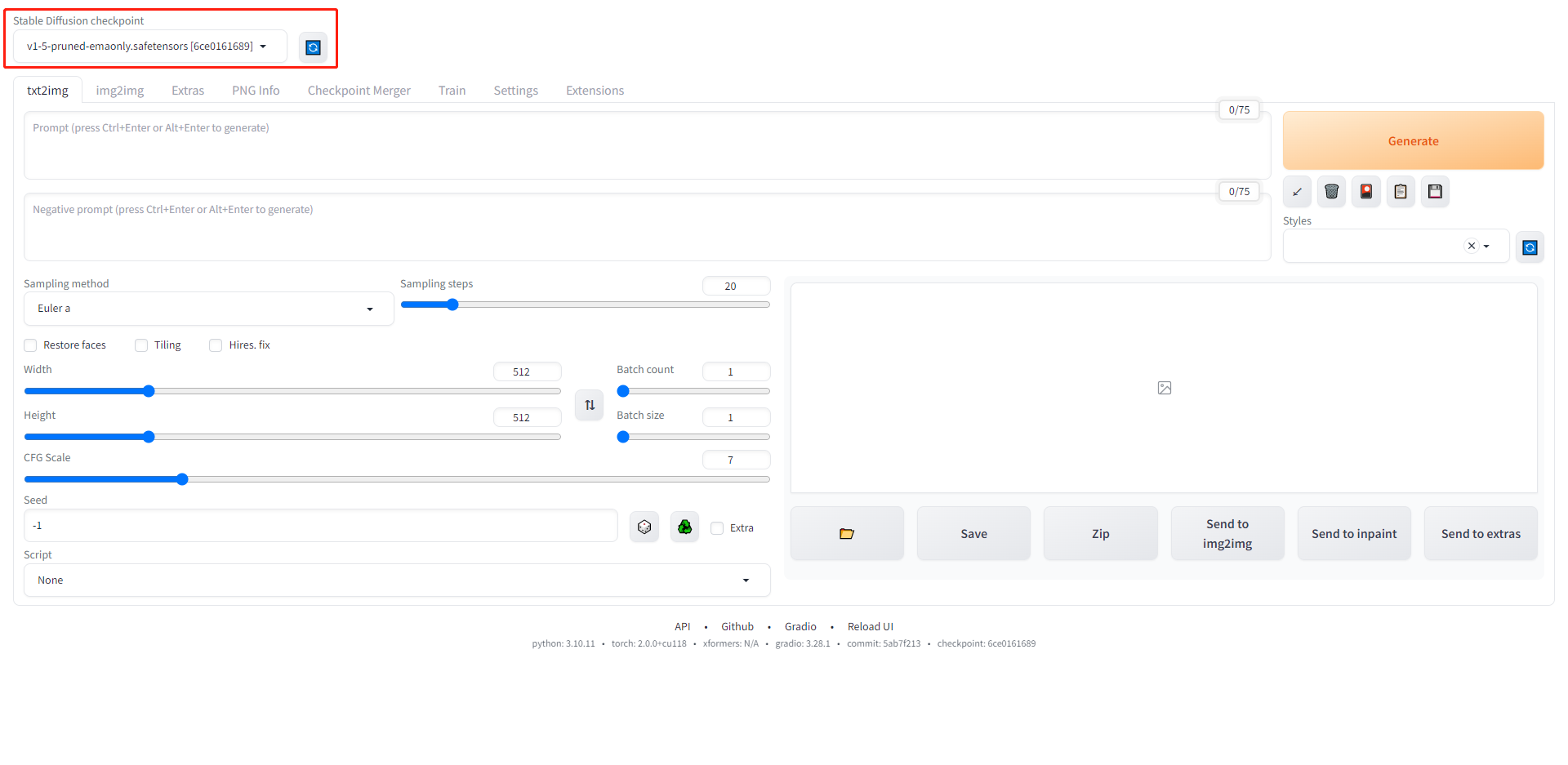 左上角显示的是你当前加载的基础模型,可以从这里进行切换,中间区域就是常用的基本功能模块。 本文主要介绍txt2img的基本参数使用。
左上角显示的是你当前加载的基础模型,可以从这里进行切换,中间区域就是常用的基本功能模块。 本文主要介绍txt2img的基本参数使用。
prompt&negative prompt
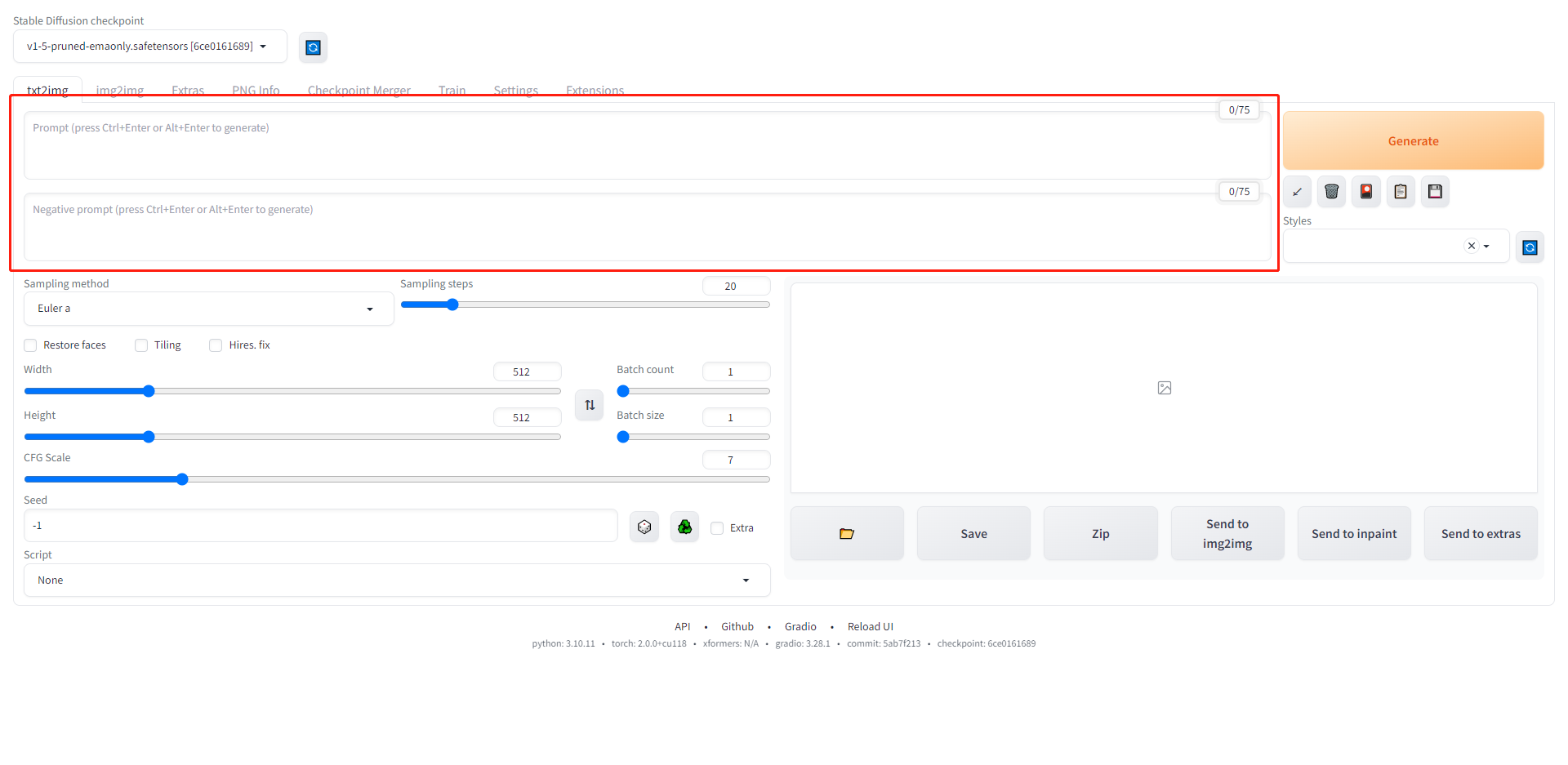 stable diffusion的大部分模型对于完整的句子没有太强的理解力,因此prompt主要通过关键词形式进行描述,两个提示词之间用英文逗号分割,默认情况下靠前的提示词会优先于靠后的提示词。 提示词应当包含以下内容:
stable diffusion的大部分模型对于完整的句子没有太强的理解力,因此prompt主要通过关键词形式进行描述,两个提示词之间用英文逗号分割,默认情况下靠前的提示词会优先于靠后的提示词。 提示词应当包含以下内容:
- **主体内容:**描述画面的主体内容,可以包含一个主要形象和相关的形容,比如1 twenty years old girl
- **画面质量:**描述画面所需的清晰度、真实度之类的信息,比如photo realistic,high quality,materpiece等
- **画面风格或艺术家(非必须):**引用艺术家的名字或者风格名称,可以一定程度上修改你的图片风格,但是会受到基础模型本身的限制,比如cyberpunk
- **画面角度或摄影参数(非必须):**如果希望获取更加接近照片的效果,可以通过输入一些摄影参数、相机型号或者镜头角度的描述词,可能会输出更像真实摄影作品的效果,比如side view,closeup shot,Fujifilm XT3等
如果需要其他的一些细节,也可以自己探索更加详细的描述词。但需要注意当描述词过多时,每个描述词的效力可能会开始下降,有些描述词将会几乎失去作用,因此建议经过多次实验,尽量精简你的描述词。 negative prompt相对于prompt,用于描述你不希望在画面中出现的内容,语法与prompt完全一致。 prompt要如何写,是一个系统性的知识,将会在后续的教程中进一步说明。
采样参数
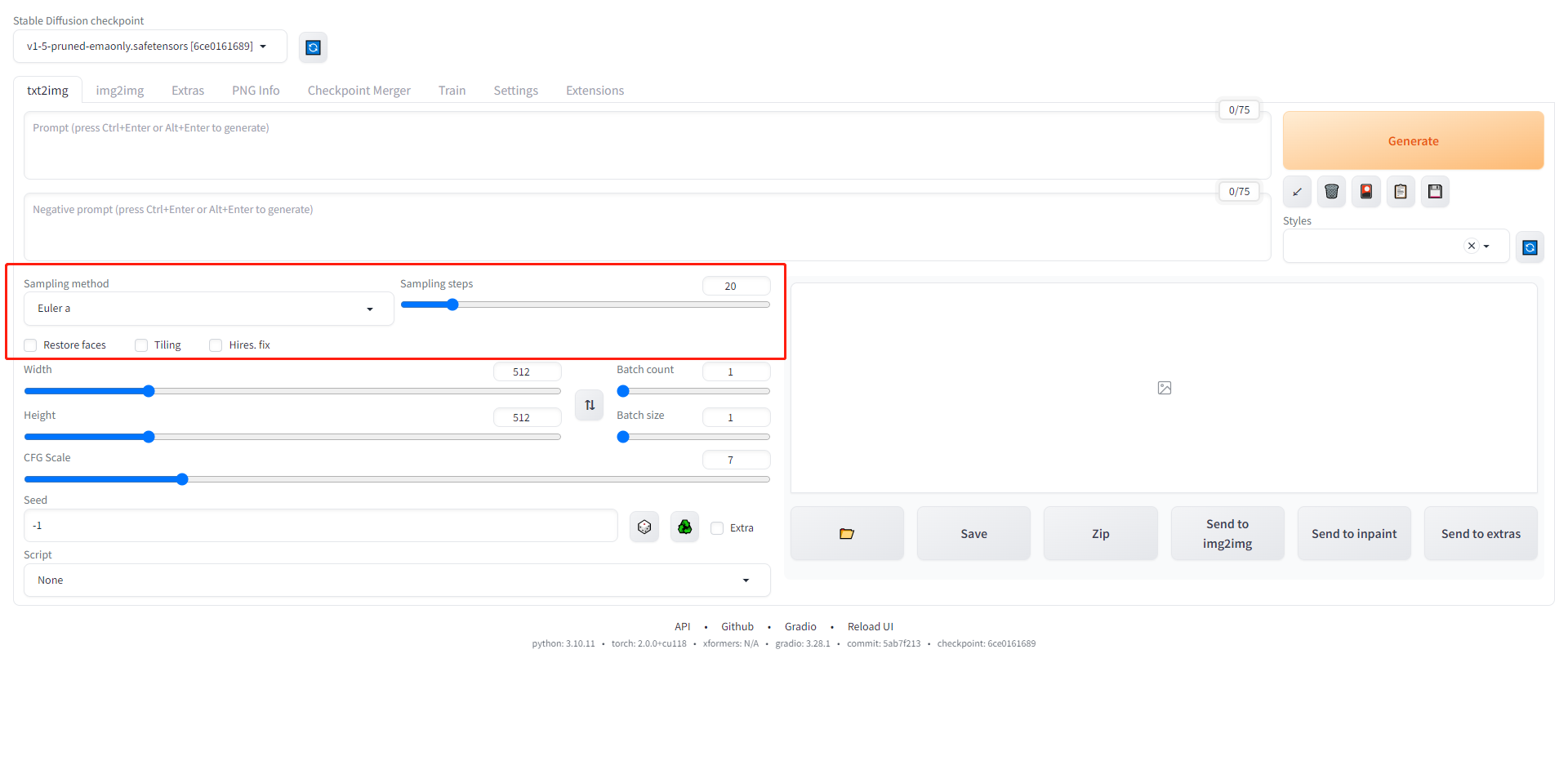 采样相关参数对于初学者来说可能效果并不明显 采样方法(sampling method):可以理解为从噪点中生成图片的多种路径,其中可以选择很多种方法,但是从效果上看,只要步数合适的情况下,实际上都可以画出差不多的图片,其中的区别主要是运行速度、资源占用量和步数的区别,因此本教程中暂时不进行展开 采样步数(sampling steps):可以简单理解为系统处理一张图片所需的迭代步骤,制作一个好的图像需要合适的采样步数,过低会导致图片尚未生成,过高则可能会将已经成型的图片过分加工成无法辨认的内容,一般采样步数都在20-30之间 预设功能——面部修复(Restore face):顾名思义,该功能引入了一个默认的模型用于修复包含人脸的图片中的人脸表现,可以大大降低画出可怕的人脸的概率 预设功能——平铺图像(Tiling):该功能开启后会尝试创造可以无缝平铺的图片,用于纹理的制作非常有用,生成的图像拼接在一起时内容可以连接 预设功能——高清修复(Hires.fix):该功能开启后,在正常的采样步数结束后,将会自动基于生成的图片进行扩大分辨率的图生图,新生成的图片会有一定的重绘,重绘程度可以通过选择后弹出的重绘幅度参数调控,值越大则重绘越多 预设功能首次运行的时候,会需要加载相关的模型,因此首次运行需要等待加载完成,会多耗费一些时间。
采样相关参数对于初学者来说可能效果并不明显 采样方法(sampling method):可以理解为从噪点中生成图片的多种路径,其中可以选择很多种方法,但是从效果上看,只要步数合适的情况下,实际上都可以画出差不多的图片,其中的区别主要是运行速度、资源占用量和步数的区别,因此本教程中暂时不进行展开 采样步数(sampling steps):可以简单理解为系统处理一张图片所需的迭代步骤,制作一个好的图像需要合适的采样步数,过低会导致图片尚未生成,过高则可能会将已经成型的图片过分加工成无法辨认的内容,一般采样步数都在20-30之间 预设功能——面部修复(Restore face):顾名思义,该功能引入了一个默认的模型用于修复包含人脸的图片中的人脸表现,可以大大降低画出可怕的人脸的概率 预设功能——平铺图像(Tiling):该功能开启后会尝试创造可以无缝平铺的图片,用于纹理的制作非常有用,生成的图像拼接在一起时内容可以连接 预设功能——高清修复(Hires.fix):该功能开启后,在正常的采样步数结束后,将会自动基于生成的图片进行扩大分辨率的图生图,新生成的图片会有一定的重绘,重绘程度可以通过选择后弹出的重绘幅度参数调控,值越大则重绘越多 预设功能首次运行的时候,会需要加载相关的模型,因此首次运行需要等待加载完成,会多耗费一些时间。
图片尺寸
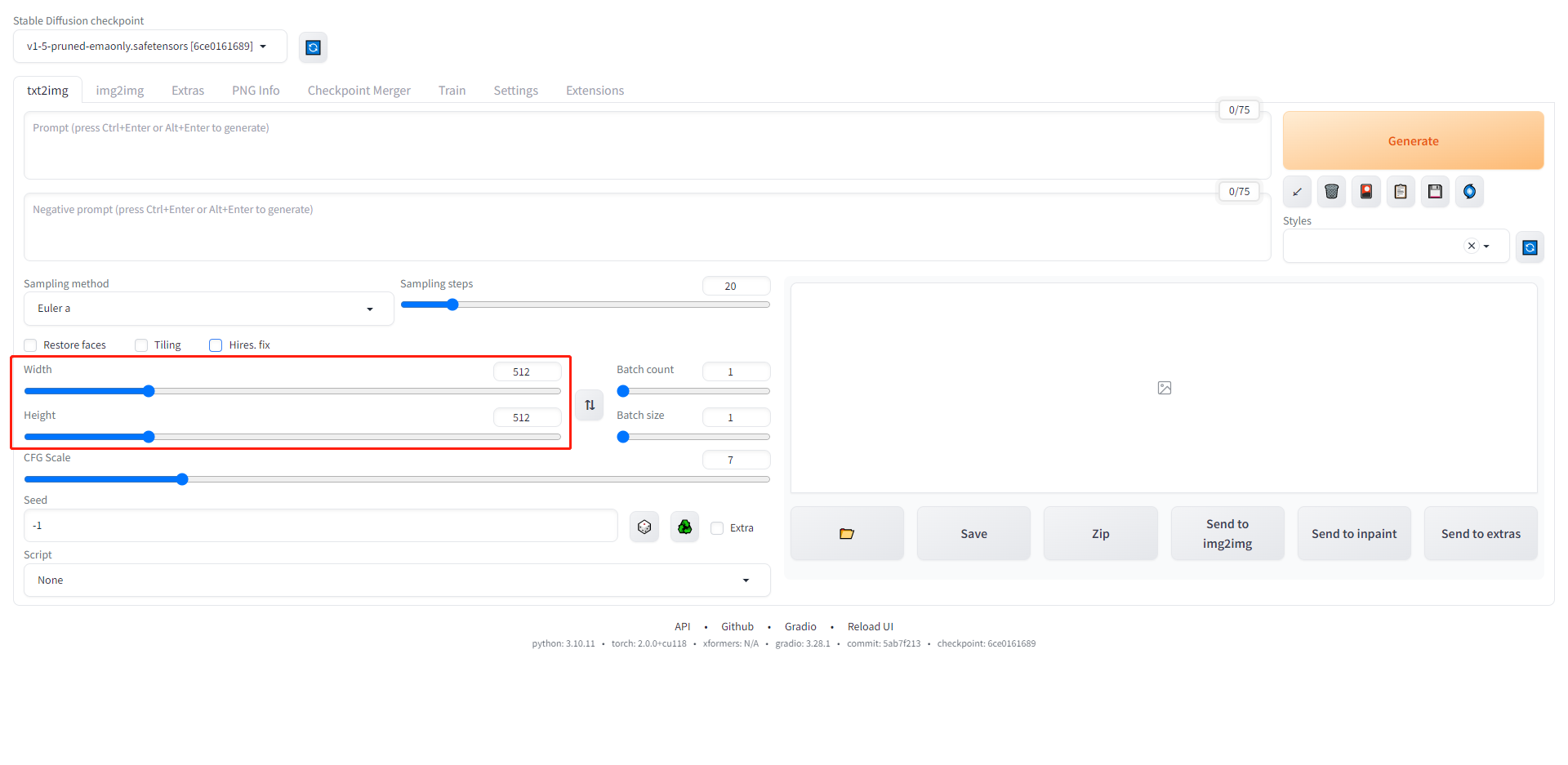 尺寸的参数非常直观,分别设定图片的宽(width)和高(height),需要注意的是越大的图片生成所需显存越高,因此如果没有足够的显存,建议图片尺寸从较小开始逐步尝试扩大。 一般模型在随着图片尺寸变大的时候,图片的细节也会更多,这可能是模型训练时所用的图片尺寸影响的,因此使用Hire.fix功能提高图片分辨率一定程度上也可以提高图片的质量。
尺寸的参数非常直观,分别设定图片的宽(width)和高(height),需要注意的是越大的图片生成所需显存越高,因此如果没有足够的显存,建议图片尺寸从较小开始逐步尝试扩大。 一般模型在随着图片尺寸变大的时候,图片的细节也会更多,这可能是模型训练时所用的图片尺寸影响的,因此使用Hire.fix功能提高图片分辨率一定程度上也可以提高图片的质量。
批次参数
批次参数可以理解为控制一次启动生成的图片数量,但是两个参数的作用方式不一样 批次数量(Batch count):决定了一次生成操作,模型会运行多少次,每次运行都会产出一批图片 批次容量(Batch size):决定了一次运行产生多少张图片 批次数量的增加只会线性增加一次启动的处理时间,原理上它和启动一次获得结果之后再进行一次运行是几乎没有区别的。而批次容量的增加则会增加显存的占用,因为它尝试并行产生多张图片。 最终你点击一次”生成”按钮,运行完成后生成的图片数量应该时批次数量*批次容量。一般可以先通过生成单张图片确认prompt有效性,然后通过增加批次数量和容量进行批量产出
随机性参数
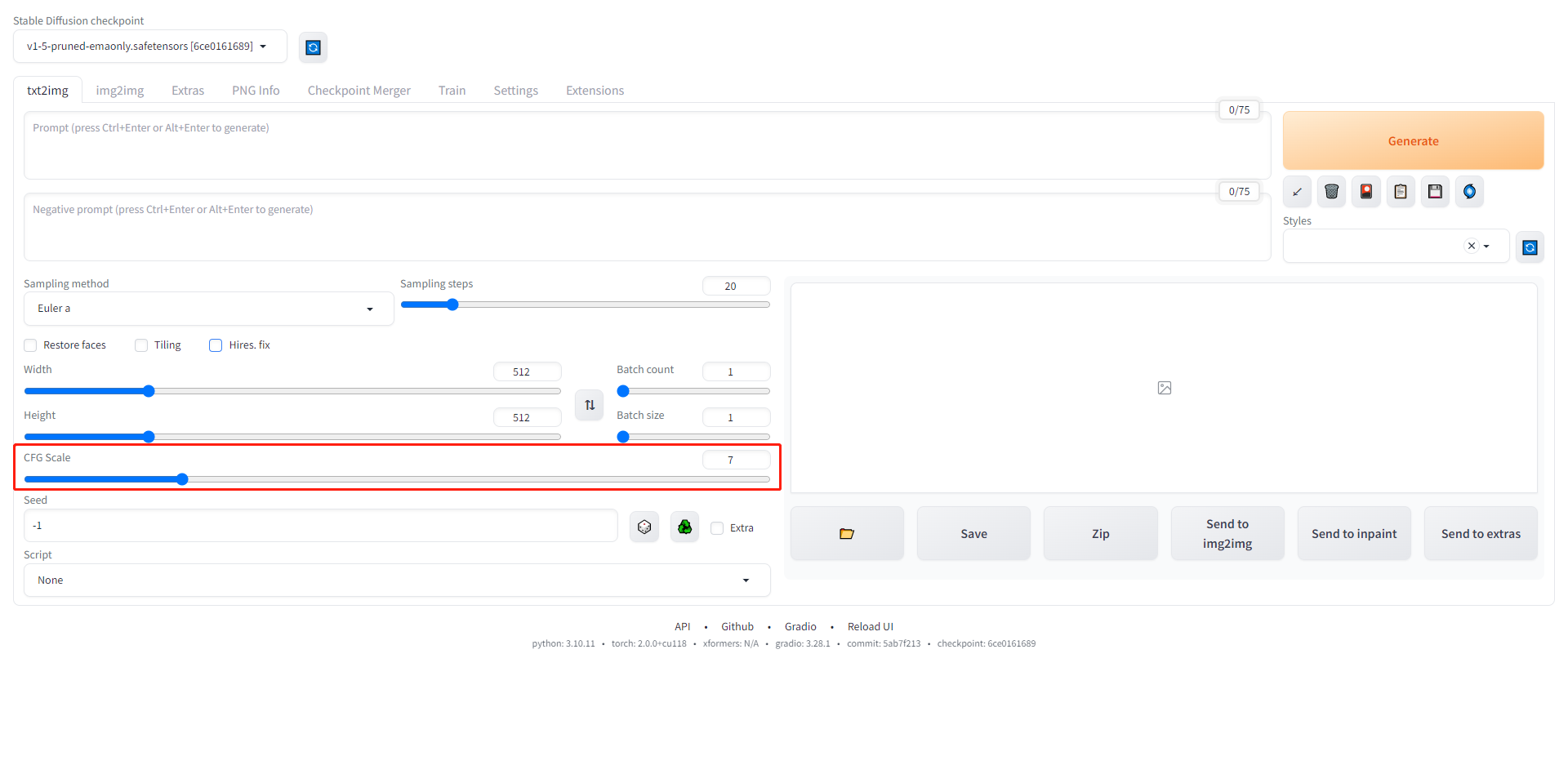 CFG Scale参数主要影响了你的提示词多大程度上影响图片,值越大则图片会越符合提示词的描述,但是过大的情况下,也可能出现图片的崩坏。系统默认选择了7,一般在5-10之间进行选择。
CFG Scale参数主要影响了你的提示词多大程度上影响图片,值越大则图片会越符合提示词的描述,但是过大的情况下,也可能出现图片的崩坏。系统默认选择了7,一般在5-10之间进行选择。
辅助功能
可以看到生成按钮下还有几个小的按钮,这些主要是一些辅助性质的功能  它们从左到右分别是 **生成数据解析(箭头):**如果你有一个完整的generation data,你可以将它输入到prompt输入框中,点击这个按钮,将会按照语法将generation data中的全部参数自动填充到各自的位置。在C站的图片详情右侧,一般能获取到相关图片的generation data。这里是一个例子,可以用于尝试:
它们从左到右分别是 **生成数据解析(箭头):**如果你有一个完整的generation data,你可以将它输入到prompt输入框中,点击这个按钮,将会按照语法将generation data中的全部参数自动填充到各自的位置。在C站的图片详情右侧,一般能获取到相关图片的generation data。这里是一个例子,可以用于尝试:
1 | |
清空prompt(垃圾桶):这个功能很容易理解,就是可以清空所有的prompt内容,注意它不会清空其他参数 辅助模型(油画):这个功能会展开一个模型画廊,帮助你浏览你已经下载的基础模型和辅助模型,其中会分为多个类型,关于辅助模型的使用,我们会在后续的教程中继续展开 应用/存储风格(文件/软盘):你可以使用存储按钮将当前的prompt+negative prompt保存为一个固定的组合,在下面Styles中选择存储的组合,再点击应用按钮,会将存储的关键词填充到prompt和negative prompt中。注意这个填充过程是在已有的prompt基础上叠加的而非替换。
5. 一般错误解决
科学上网冲突
当开启代理的情况下,启动webui之后,尝试生成图片一定几率会遇到错误,提示为 “ Something went wrong Expecting value: line 1 column 1 “ 这是webui和代理配置的冲突导致的,可以尝试在启动文件中增加参数来解决,具体步骤如下:
- 在安装目录中找到webui-user.bat文件(没错就是启动用的文件),右键选择编辑
- 在COMMANDLINE_ARGS中增加”–no-gradio-queue”,具体语法如下:

- 重新启动webui-user.bat,就可以在代理启动的情况下愉快的使用了
xformers不存在
不知道因为什么原因,在正常启动该webui时,应当加载的xformers总是会加载失败,虽然没有它也可以使用,但是xformers可以有效的降低项目对显存的需求量,因此最好还是加载上。这个问题同样可以通过在启动文件中增加参数解决。步骤和上面的步骤一样只是增加一个参数”–reinstall-xformers –xformers”。 注意两个参数之间用空格隔开,重新启动后程序会尝试重新安装xformers并启动,这样webui就会成功带有xformers启动了
6. 扩展信息
关键目录
整个stable-diffusion-webui项目安装完成后将会形成一个这样的目录 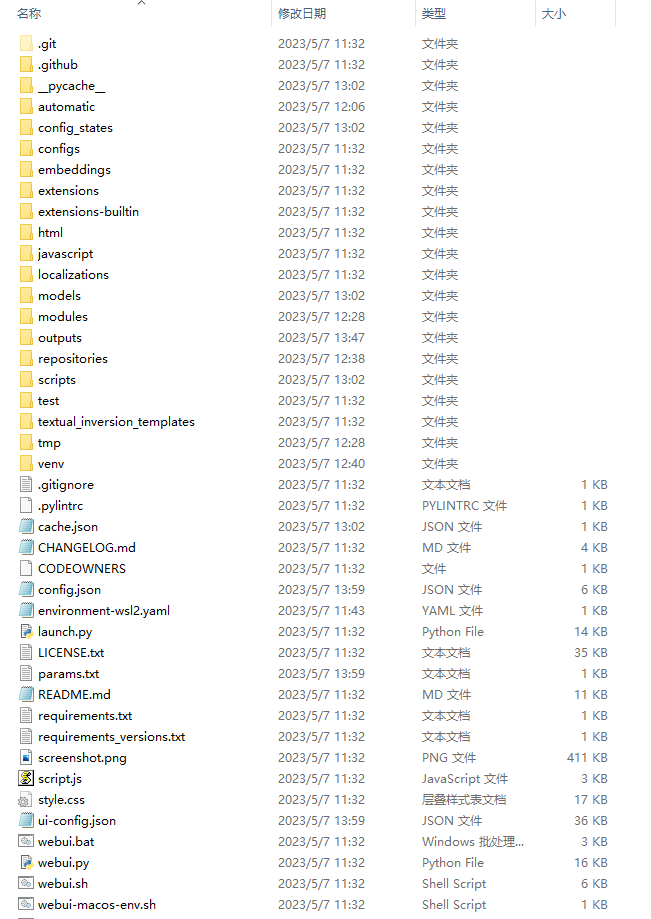 其中: automatic目录中存储了该项目的虚拟环境文件 embeddings目录中存放Textual Inversion 辅助模型 extensions目录中存放的是webui插件文件,一些无法通过webui直接安装的插件,一般是解压后直接放在该文件夹内 models目录用于保存基础模型和一些辅助模型 outputs目录默认存储了你每次生成的图片结果 这些目录都是我们在使用stable diffusion webui时会经常使用的
其中: automatic目录中存储了该项目的虚拟环境文件 embeddings目录中存放Textual Inversion 辅助模型 extensions目录中存放的是webui插件文件,一些无法通过webui直接安装的插件,一般是解压后直接放在该文件夹内 models目录用于保存基础模型和一些辅助模型 outputs目录默认存储了你每次生成的图片结果 这些目录都是我们在使用stable diffusion webui时会经常使用的
插件推荐
stable diffusion webui默认提供了一个插件市场,可以安装多种不同的插件,扩展该应用的能力。个人认为比较必须的插件主要是以下两个
controlnet:一个帮助你更好的控制生成内容的插件,支持通过深度图、pose骨骼图、线稿等多种内容引导生成新的图片,是商业化作图必备的一个插件。它的使用也比较复杂,后续可能会推出对应的教程说明
相关链接:ControlNet GitHub
civitai helper:一个用于管理C站中下载的模型的工具,支持自动扫描模型下载预览图、自动加载模型prompt、自动扫描模型新版本等功能。